class: center, middle, inverse, title-slide # Wissenschaftliches Programmieren mit R ## Vektoren allerorten ### Andreas Blaette ### 27. April 2021 --- # Installationen - Für die ersten Schritte beim Programmieren mit R beschäftigen wir uns mit Vektoren als grundlegender Datenstruktur -- - Dafür wir brauchen wir später Stoff zum Ausprobieren - wir nutzen Testdaten, die in den Paketen `tm` und `polmineR` enthalten sind. ```r install.packages("tm") install.packages("polmineR") ``` - Außerdem installieren wir ein Datenpaket mit Daten der *German Longitudinal Election Study (GLES)* ```r install.packages("drat") # creation and use of CRAN-like repos drat::addRepo("polmine") getOption("repos") install.packages("gles") ``` - Was in diesen Paketen verborgen ist ... erfahren Sie noch früh genug! --- # Vektoren Vektoren sind die grundlegende Datenstruktur in R. Sie bestehen immer aus einer Datenart: -- ... logischen Werten (`logical`) ```r logo <- c(T, F, F, T) logo <- c(TRUE, FALSE, FALSE, TRUE) # mehr Tipparbeit, aber expressiver ``` -- ... numerischen Werten (`numeric`) -> Quelle: [Projektion FGW](https://www.forschungsgruppe.de/Startseite/) ```r fgw_exp <- c(39, 16, 9, 5, 7, 18, 6) ``` -- ... Textzeichen (`character`) ```r parties <- c("CDU/CSU", "SPD", "AfD", "FDP", "LINKE", "GRÜNE", "Sonstige") party_colors <- c("black", "red", "blue", "yellow", "pink", "green", "grey") ``` -- Vektoren können in Variablen gespeichert werden (Zuweisung mit dem Pfeil `<-`). Man sollte sich von Anfang an eine aussagekräftige Benennung von Variablen angewöhnen! --- # Numerische Vektoren ## Einfache Operationen und generische Funktionen -- ```r a <- 1:5 # eine Zahlenreihe b <- 6:10 # eine zweite Zahlenreihe ``` - Anwendung "generischer" Funktionen ```r x <- c(a, b) # numerische Vektoren verknüpfen ("c"für combine) head(x) # Anfang eines Vektors ansehen ``` ``` ## [1] 1 2 3 4 5 6 ``` ```r tail(x) # Ende eines Vektors ansehen ``` ``` ## [1] 5 6 7 8 9 10 ``` ```r is.numeric(x) # Auf Klasse 'numeric' prüfen - vgl. is.character() etc. ``` ``` ## [1] TRUE ``` --- # Einfache Operationen mit Vektoren ### Typumwandlungen ```r as.numeric(logo) # Typ-Umwandlung von logisch nach numerisch ``` ``` ## [1] 1 0 0 1 ``` ```r as.character(fgw_exp) ``` ``` ## [1] "39" "16" "9" "5" "7" "18" "6" ``` ### Wiederholungen ```r rep(3, times = 4) # einfache Wiederholung ``` ``` ## [1] 3 3 3 3 ``` ```r rep(c(1,2,3), times = 2) # Wiederholung einer Reihe ``` ``` ## [1] 1 2 3 1 2 3 ``` --- # Mit Vektoren rechnen ```r a <- c(1,2,3) b <- c(4,5,6) a + b ``` ``` ## [1] 5 7 9 ``` ```r a * b ``` ``` ## [1] 4 10 18 ``` ```r a / b ``` ``` ## [1] 0.25 0.40 0.50 ``` ```r sum(fgw_exp) # auch: mean(fgw_exp), sd(fgw_exp) ``` ``` ## [1] 100 ``` *Merke: In R ist die Vektorisierung von Operationen schnell und effizient! Vectorize whenever you can!* --- # Benannte Vektoren (named vectors) ```r names(fgw_exp) <- parties # Zuweisung von Namen fgw_exp ``` ``` ## CDU/CSU SPD AfD FDP LINKE GRÜNE Sonstige ## 39 16 9 5 7 18 6 ``` ```r fgw_exp <- c( "CDU/CSU" = 39, # Anführungszeichen, wenn Zeichen wie ()[]! etc. enthalten SPD = 16, AfD = 9, FDP = 5, LINKE = 7, GRÜNE = 18, # Umlaute (und Sonderzeichen) können unendlich tückisch sein ... Sonstige = 6 ) fgw_exp ``` ``` ## CDU/CSU SPD AfD FDP LINKE GRÜNE Sonstige ## 39 16 9 5 7 18 6 ``` --- # Unsere erste Visualisierung! ```r barplot(height = fgw_exp) ``` 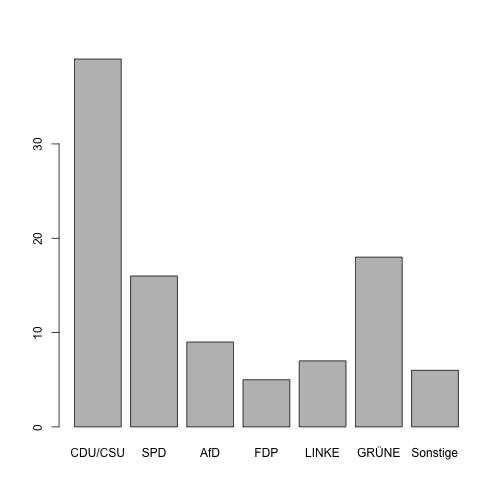<!-- --> --- # Unsere zweite Visualisierung! ```r barplot(height = fgw_exp, names.arg = names(fgw_exp), col = party_colors) ``` 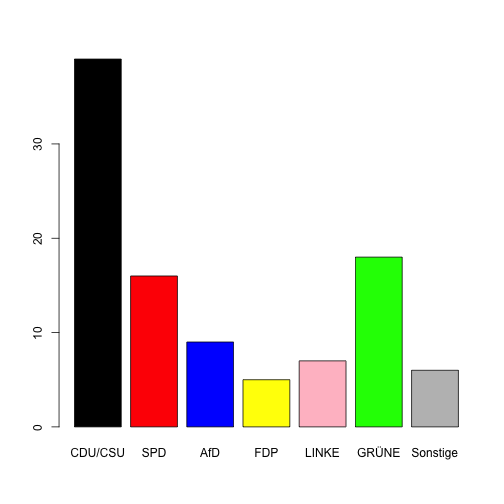<!-- --> --- # Indizierung ```r spd <- fgw_exp[2] # nur SPD fgw_exp[1:6] # ohne "Sonstige" ``` ``` ## CDU/CSU SPD AfD FDP LINKE GRÜNE ## 39 16 9 5 7 18 ``` ```r centre_left <- fgw_exp[c("SPD", "LINKE", "GRÜNE")] # ``` Erste Erkenntnissee über Koalitionen ... ```r sum(centre_left) ``` ``` ## [1] 41 ``` ```r sum(fgw_exp[c("CDU/CSU", "FDP")]) ``` ``` ## [1] 44 ``` --- # Logische Operatoren ```r fgw_exp["CDU/CSU"] >= 30 ``` ``` ## CDU/CSU ## TRUE ``` ```r fgw_exp["FDP"] < 5 ``` ``` ## FDP ## FALSE ``` ```r fgw_exp > 10 ``` ``` ## CDU/CSU SPD AfD FDP LINKE GRÜNE Sonstige ## TRUE TRUE FALSE FALSE FALSE TRUE FALSE ``` ```r fgw_exp[fgw_exp > 10] ``` ``` ## CDU/CSU SPD GRÜNE ## 39 16 18 ``` --- # Funktionen für (numerische) Vektoren ```r length(fgw_exp) # wichtig, um durch Werte zu iterieren - 1:length(fgw_exp) ``` ``` ## [1] 7 ``` ```r order(fgw_exp) # Reihenfolge ``` ``` ## [1] 4 7 5 3 2 6 1 ``` ```r order(fgw_exp, decreasing = TRUE) # wie könnte das noch gemacht werden? ``` ``` ## [1] 1 6 2 3 5 7 4 ``` ```r fgw_exp[order(fgw_exp, decreasing = TRUE)] ``` ``` ## CDU/CSU GRÜNE SPD AfD LINKE Sonstige FDP ## 39 18 16 9 7 6 5 ``` --- # Einfache statistische Maße ```r max(fgw_exp) # Maximalwert ``` ``` ## [1] 39 ``` ```r min(fgw_exp) # minimaler Wert ``` ``` ## [1] 5 ``` ```r mean(fgw_exp) # Mittelwert ``` ``` ## [1] 14.28571 ``` ```r sd(fgw_exp) # Standardabweichung ``` ``` ## [1] 11.99603 ``` --- # Lokalisierung bestimmter Werte ```r which(fgw_exp == max(fgw_exp)) ``` ``` ## CDU/CSU ## 1 ``` ```r fgw_exp[which(fgw_exp == max(fgw_exp))] ``` ``` ## CDU/CSU ## 39 ``` ```r fgw_exp[which(fgw_exp > 10)] ``` ``` ## CDU/CSU SPD GRÜNE ## 39 16 18 ``` --- # Funktionen für character-Vektoren ```r library(polmineR) words <- get_token_stream("GERMAPARLMINI", p_attribute = "word") length(words) ``` ``` ## [1] 222201 ``` ```r head(words) ``` ``` ## [1] "Guten" "Morgen" "," "meine" "sehr" "verehrten" ``` ```r head(toupper(words)) ``` ``` ## [1] "GUTEN" "MORGEN" "," "MEINE" "SEHR" "VEREHRTEN" ``` ```r tolower(words) %>% head() ``` ``` ## [1] "guten" "morgen" "," "meine" "sehr" "verehrten" ``` --- # Funktionen für character-Vektoren (II) ```r wordcount <- table(words) head(wordcount) ``` ``` ## words ## _ - -- -0 -15 -auch ## 1 1452 3 1 1 2 ``` ```r stopwords <- tm::stopwords("de") detect_stopwords <- words %in% stopwords word_count <- table(words[!words %in% stopwords]) # Negation durch ! tail(word_count) ``` ``` ## ## zwölfmal Zwölftens zynisch Zynismus Zypries Zypris ## 1 1 3 1 1 1 ``` --- # Polierarbeit ```r noise <- c(",", ".", ":", ")", "(", "/", "-", "!", "[", "]", "?", ";", '"') word_count_denoised <- word_count[!names(word_count) %in% noise] head(word_count_denoised) ``` ``` ## ## _ -- -0 -15 -auch -aus ## 1 3 1 1 2 1 ``` ```r word_count_sorted <- word_count_denoised[order(word_count_denoised, decreasing = TRUE)] head(word_count_sorted, 10) ``` ``` ## ## Sie dass Beifall Das Wir FDP CDU CSU Ich SPD ## 2280 1678 1594 1341 1100 999 952 943 896 861 ``` --- # Meine erste Wortwolke ```r wordcloud::wordcloud( words = names(word_count_sorted)[1:50], freq = unname(word_count_sorted)[1:50], colors = rep(palette(), 10)[1:50] ) ``` <!-- --> --- # Übungsaufgaben <br/><br/> 1. Was ist der Anteil der *stopwords* am Korpus? 2. Wie oft tritt die Anrede 'Sie' im Korpus auf? 3. Was sind die häufigsten/seltensten Buchstaben? --- # Wenn Sie mehr wissen wollen ... - Faktoren als vierter Vektor-Typ ```r as.factor(parties) ``` ``` ## [1] CDU/CSU SPD AfD FDP LINKE GRÜNE Sonstige ## Levels: AfD CDU/CSU FDP GRÜNE LINKE Sonstige SPD ``` - Matrizen als besondere Vektoren ```r combn(parties, 2)[,1:5] # (hypothetische) Zweier-Koalitionen ``` ``` ## [,1] [,2] [,3] [,4] [,5] ## [1,] "CDU/CSU" "CDU/CSU" "CDU/CSU" "CDU/CSU" "CDU/CSU" ## [2,] "SPD" "AfD" "FDP" "LINKE" "GRÜNE" ``` - `integer`-Vektoren als Spezialfall numerischer Vektoren ```r constituencies <- c(202L, 304L, 20L) ``` --- # NA-Werte (not available) ```r foo <- c(NA, 3, 7, NA, 4) foo ``` ``` ## [1] NA 3 7 NA 4 ``` ```r is.na(foo) # auf NA testen ``` ``` ## [1] TRUE FALSE FALSE TRUE FALSE ``` ```r sum(foo) ``` ``` ## [1] NA ``` ```r sum(foo, na.rm = TRUE) # NA-Werte aus Summenbildung ausschließen ``` ``` ## [1] 14 ```